
Task : Coin Guess
- develop a model for a “probability matching” experiment
- Experiment Flow:
- presented with a screen saying “Choose”
- either presses the ‘h’ or ‘t’
- h = heads
- t = tails
- key pressed –> screen cleared
- feedback of correct answer (h / t ) holds for 1s
- Condition :
- 48 trails
- 90% of the 48 trials, the correct answer is head
- fit data: (each block contain 12 trail) proportion of “head” choice
- 1st block : 0.664
- 2nd block : 0.778
- 3rd block : 0.804
- 4th block : 0.818
- should run multiple times of the experiment and average results
- reference (goal)
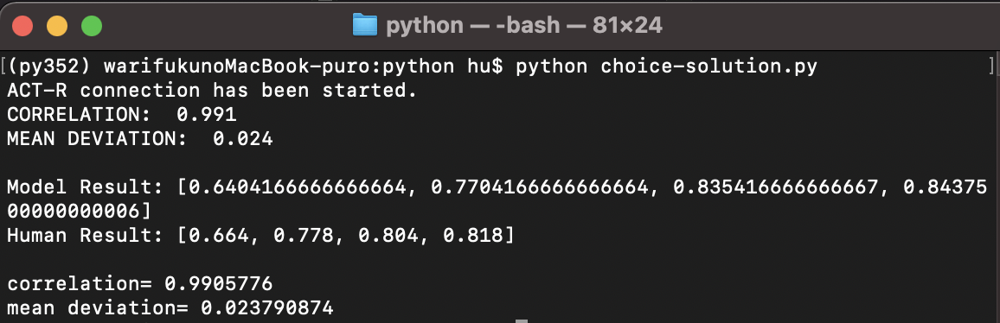
- R = 0.994
- MD = 0.016
- parameter tuning
- noise in the utilities (set by the :egs parameter)
- rewards associated with successful and unsuccessful responses.
Example experiment functions
- choice-model.lisp
- choice.lisp
- useful commands:
- reset
- run
- run_full_time(float amout_of_time)
- install_device()
- correlation()
- mean_deviation()
Solution
-
Task
import actr
import numpy as np
# actr.load_act_r_model("ACT-R:tutorial;unit6;choice-model.lisp")
actr.load_act_r_model("ACT-R:tutorial;unit6;choice-model-solution.lisp")
choice_data = [0.664, 0.778, 0.804, 0.818]
response = False
virtual_mode = True
def dominant_ratio(response):
if response.count("h") > response.count("t"):
dominant = "h"
else:
dominant = "t"
return np.mean(np.array(response)==dominant)
def respond_to_key_press (model,key):
global response
response = key
def trial(window,probability,person=True):
global response
actr.add_command("choice-response",respond_to_key_press,"Choice task key response")
actr.monitor_command("output-key","choice-response")
actr.add_text_to_exp_window (window, 'choose', x=50, y=100)
response = ''
if person:
while response == '':
actr.process_events()
else:
actr.run(1,not virtual_mode)
actr.clear_exp_window(window)
if actr.random(1.0) < probability:
answer = 'heads'
else:
answer = 'tails'
actr.add_text_to_exp_window (window, answer, x=50, y=100)
start = actr.get_time(False)
if person:
while (actr.get_time(False) - start) < 1000:
actr.process_events()
else:
actr.run(1,not virtual_mode)
actr.clear_exp_window(window)
actr.remove_command_monitor("output-key","choice-response")
actr.remove_command("choice-response")
return response
def block(block_id,probability,person=True):
block_res = []
window = actr.open_exp_window("Choice Experiment",visible=False)
actr.install_device(window)
for i in range(12):
response = trial(window,probability,person)
block_res.append(response)
res = dominant_ratio(block_res)
#print("Block-",block_id+1,"\tAccuracy=",hratio)
return res
def Experiment(num_block=4,probability=0.9,person=False):
result_list = []
for i in range(num_block):
result_list.append(block(i,probability,person))
return result_list
def compare(n=100):
result_list = []
for i in range(n):
result_list.append(Experiment(probability=0.9))
result_list.append(Experiment(probability=0.1))
result_list = np.array(result_list)
avg_result = list(np.mean(result_list,axis=0))
r=actr.correlation(avg_result,choice_data)
md=actr.mean_deviation(avg_result,choice_data)
print()
print("Model Result:",avg_result)
print("Human Result:",choice_data)
print()
print("correlation=",r)
print("mean deviation=",md)
if __name__ == "__main__":
compare(100)
-
Model
(clear-all)
(define-model choice-solution
;(sgp :seed (200 4))
(sgp :v nil :ul t :egs 3 :esc t)
(chunk-type goal state)
(chunk-type response val)
(add-dm
(start isa chunk)
(attending-choose isa chunk) (respond isa chunk)
(attending-feedback isa chunk) (read-feedback isa chunk) (done isa chunk)
(goal isa goal state start)
)
(install-device '("motor" "keyboard"))
(P start
=goal>
isa goal
state start
==>
=goal>
isa goal
state attending-choose
+visual-location>
)
(P attend-letter
=goal>
ISA goal
state attending-choose
=visual-location>
?visual>
state free
==>
+visual>
cmd move-attention
screen-pos =visual-location
=goal>
ISA goal
state respond
)
(p respond-t
=goal>
isa goal
state respond
=visual>
isa visual-object
value "choose"
;(!print! =val)
?manual>
state free
?imaginal>
state free
==>
+manual>
cmd press-key
key "t"
+imaginal>
isa response
val "tails"
=goal>
isa goal
state attending-feedback
+visual-location>
)
(p respond-h
=goal>
isa goal
state respond
=visual>
isa visual-object
value "choose"
;(!print! =val)
?manual>
state free
?imaginal>
state free
==>
+manual>
cmd press-key
key "h"
+imaginal>
isa response
val "heads"
=goal>
isa goal
state attending-feedback
+visual-location>
)
(p attending-feedback
=visual-location>
=goal>
isa goal
state attending-feedback
==>
=goal>
isa goal
state read-feedback
+visual-location>
:attended nil
)
(p read-feedback
=goal>
ISA goal
state read-feedback
=visual-location>
?visual>
state free
==>
+visual>
cmd move-attention
screen-pos =visual-location
=goal>
ISA goal
state done
)
(p done-correct
=goal>
isa goal
state done
=visual>
isa visual-object
value =val
=imaginal>
val =val
==>
=goal>
state start
)
(p done-wrong
=goal>
isa goal
state done
=visual>
isa visual-object
value =val
=imaginal>
- val =val
==>
=goal>
state start
)
(goal-focus goal)
;(spp respond-h :u 10)
;(spp respond-t :u 10)
(spp attend-letter :reward 0)
(spp done-correct :reward 10)
)
-
Parameter tuning:
- :ens = 3
- reward of success = 10
Results
- R = 0.991
- MD = 0.023