Blackjack

Task description
- do not know:
- opponent’s strategy
- the distribution of cards in the decks
- model ‘s description:
-
At the start of the game, can I remember a similar situation and the action I took? If so, make that action. If not then I should stay. When I get the feedback is there some pattern in the cards, actions, and results which indicates the action I should have taken? If so create a memory of the situation for this game and the action to take. Otherwise, just wait for the next hand to start.
-
- two things can be done to make it better:
- the information which it considers when making its initial choice
- how it interprets the feedback so that it creates chunks which have appropriate information about the actions it should take
- Change learned-info chunk-type (the current model only considers one of its own cards).
- Change the start production
- Change or replace the results-should-hit and results-should-stay productions
- Advanced improvement
- Change the noise level and the mismatch penalty parameters to adjust the learning rate or flexibility of the model.
- Add more productions to analyze the starting position either before or after retrieving an appropriate chunk.
- Provide a strategy other than just choosing to stay when no relevant information can be retrieved.
- runing the game
- play multiple hands :
-
? (onehit-hands 5) 5: bumber of hands to play
-
- return (1 4 0 0 )
- model’s wins
- the opponent’s wins
- the times when both players bust
- the times when they are tied.
- play blocks
-
? (onehit-blocks 2 5)
-
- play the experiment
-
? (onehit-learning 100)
- return :
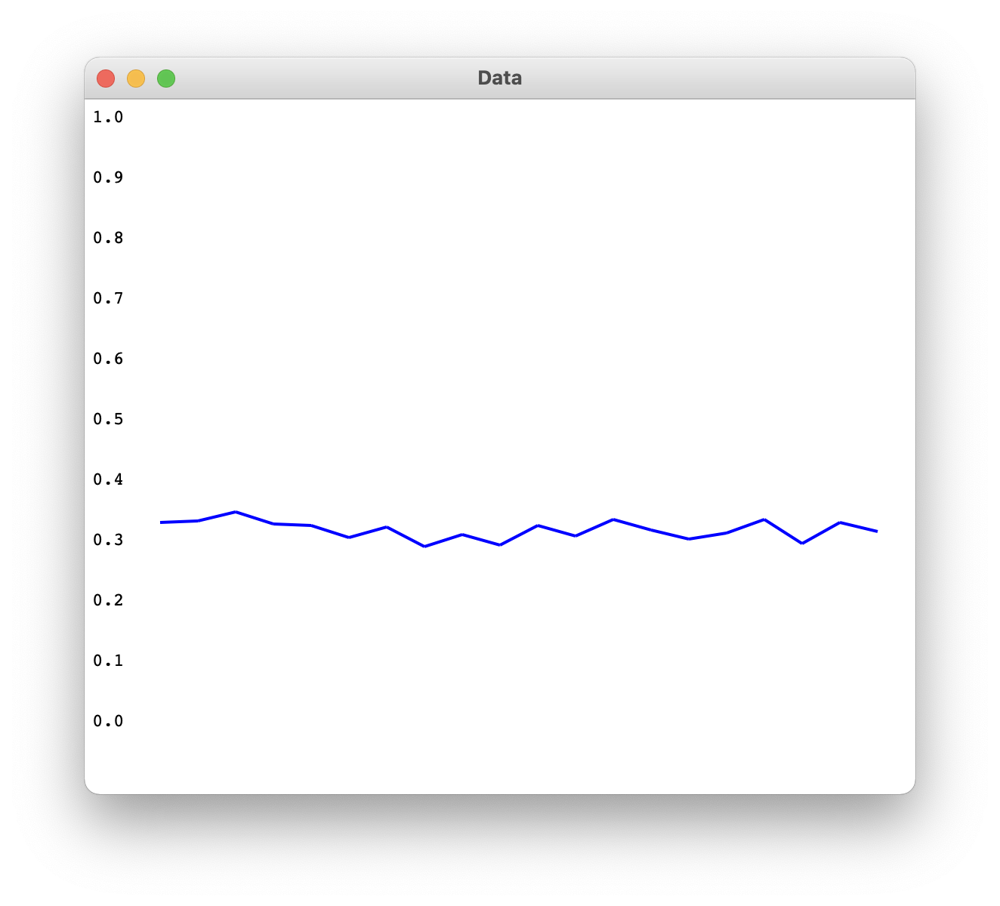
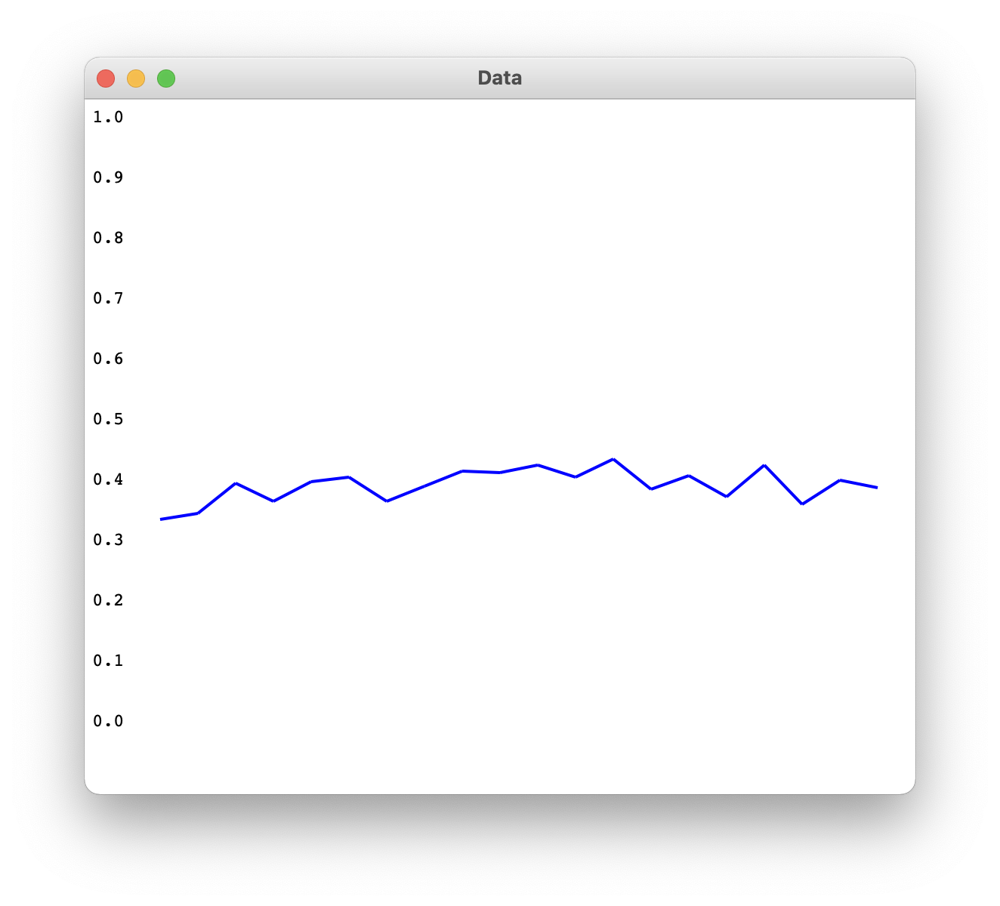
- win rates of 4 blocks of 25 hands
- win rates of 20 blocks of 5 hands (more detailed and is ploted in a graph)
-
- play yourself
-
? (play-against-model 1) 1: bumber of hands to play
-
- play multiple hands :
- default game setting:
- opponent’s strategy:
- always stays with a score of 15 or more
- card distribution:
- 1-9 : frequency = 0.077
- 10 : frequency = 0.308 (around 4 times of cards of 1-9 )
- opponent’s strategy:
- reference solution
- 勝ち率を上昇させる.improve from 37% to 40%
Model
(clear-all)
(define-model 1-hit-model
;; do not change these parameters
(sgp :esc t :bll .5 :ol t :sim-hook "1hit-bj-number-sims" :cache-sim-hook-results t :er t :lf 0)
;; adjust these as needed
(sgp :v nil :ans .2 :mp 15.0 :rt -5)
;; This type holds all the game info
(chunk-type game-state mc1 mc2 mc3 mstart mtot mresult oc1 oc2 oc3 ostart otot oresult state)
;; This chunk-type should be modified to contain the information needed
;; for your model's learning strategy
(chunk-type learned-info MSTART OSTART action)
;; Declare the slots used for the goal buffer since it is
;; not set in the model defintion or by the productions.
;; See the experiment code text for more details.
(declare-buffer-usage goal game-state :all)
;; Create chunks for the items used in the slots for the game
;; information and state
(define-chunks win lose bust retrieving start results)
;; Provide a keyboard for the model's motor module to use
(install-device '("motor" "keyboard"))
(p start
=goal>
isa game-state
state start
MSTART =c
OSTART =o
==>
=goal>
state retrieving
+retrieval>
isa learned-info
MSTART =c
OSTART =o
- action nil)
(p cant-remember-game-hit
=goal>
isa game-state
state retrieving
?retrieval>
buffer failure
?manual>
state free
==>
=goal>
state nil
!output! ("not remember and hit")
+manual>
cmd press-key
key "h")
(p cant-remember-game-stay
=goal>
isa game-state
state retrieving
?retrieval>
buffer failure
?manual>
state free
==>
=goal>
state nil
!output! ("not remember and stay")
+manual>
cmd press-key
key "s")
(p remember-game
=goal>
isa game-state
state retrieving
=retrieval>
isa learned-info
action =act
?manual>
state free
==>
=goal>
state nil
!output! (I =act)
+manual>
cmd press-key
key =act
@retrieval>)
(p results-should-hit-if-win
=goal>
isa game-state
state results
mresult win
MSTART =c
OSTART =o
- MC3 nil
?imaginal>
state free
==>
;!output! (I =outcome)
=goal>
state nil
+imaginal>
MSTART =c
OSTART =o
action "h")
(p results-should-stay-if-win
=goal>
isa game-state
state results
mresult win
MSTART =c
OSTART =o
MC3 nil
?imaginal>
state free
==>
;!output! (I =outcome)
=goal>
state nil
+imaginal>
MSTART =c
OSTART =o
action "s")
(p results-no-act-if-lose
=goal>
isa game-state
state results
mresult lose
?imaginal>
state free
==>
;!output! (I =outcome)
=goal>
state nil
+imaginal>
MSTART nil
OSTART nil
action nil)
(p results-should-stay-if-bust
=goal>
isa game-state
state results
mresult bust
MSTART =c
OSTART =o
?imaginal>
state free
==>
;!output! (I =outcome)
=goal>
state nil
+imaginal>
MSTART =c
OSTART =o
action "s")
(p results-should-stay-if-over-eighteen
=goal>
isa game-state
state results
;mresult bust
> MSTART 18
MSTART =c
OSTART =o
?imaginal>
state free
==>
;!output! (I =outcome)
=goal>
state nil
+imaginal>
MSTART =c
OSTART =o
action "s")
(p results-should-hit-if-less-twelve
=goal>
isa game-state
state results
;mresult bust
< MSTART 12
MSTART =c
OSTART =o
?imaginal>
state free
==>
;!output! (I =outcome)
=goal>
state nil
+imaginal>
MSTART =c
OSTART =o
action "h")
(spp results-should-stay-if-over-eighteen :u 10)
(spp results-should-hit-if-less-twelve :u 10)
(p clear-new-imaginal-chunk
?imaginal>
state free
buffer full
==>
-imaginal>)
)
Strategy Desicription
- if m_start < 12 , learn to hit
- if m_start > 18, learn to stay
- learn any chunks that won
- do not learn when burst or lose
Results
-
? (onehit-hands 5)
- (3 2 0 0)
-
? (onehit-blocks 2 5)
- ((1 4 0 0) (2 3 0 0))
-
? (onehit-learning 100)
-
((0.3616 0.39159998 0.4048 0.3828) (0.328 0.338 0.39000002 0.35999998 0.39200002 0.398 0.35999998 0.384 0.41 0.406 0.41799998 0.398 0.42800003 0.378 0.402 0.366 0.41799998 0.354 0.394 0.382))
- Original Results:
- Hu’s strategy implemented
-